GPU端到端目标检测YOLOV3全过程(上)
Basic Parameters:
Video: mp4, webM, avi Picture: jpg, png, gif, bmp Text: doc, html, txt, pdf, excel Video File Size: not more than 10GB batch=16, subdivisions=1 Resolution: 416 * 416, 320 * 320. Frame: 45f/s with 320 * 320. At 320 × 320 YOLOv3 runs in 22 ms at 28.2 mAP, as accurate as SSD but three times faster. AI Framework:TensorFlow, Pytorch, Mxnet, Caffe Programming Lanuage: Python/C/C++/Java Accept: application/json, text/plain, / Accept-Language: en-US, en; Files Input Parameters of Test Model : .model,.weight Files Input Parameters of Train Model : Filename, Path, Resolution,… Files Output Parameters of Train Model : .model,.weight Files Output Parameters of Test Model : Class Number,Class Name,mAP value Hardware: VGA, DVI, HDMI, DP, SDI, BNC, WIFI, Bluetooth, USB, CAN, Socket, PCIE, SD Card, Serial Port, Clock Time, SPI, Uart, I2C/I2S, GPIO, Touch Ctrl, LCD, LED, EMMC, SATA, Audio ADC Dependency Library: v4l2(Video for linux2),ffmpeg,VLC media player,opencv, CUDA,cudann,Tensorflow,Pytorch,Mxnet,Caffe,Ubuntu, darknet,udp/tcp,H264、AAC,rtmp、rtp/rtcp,ffmpeg、x264、 WebRTC、GStreamer,NEON、OpenCL、OpenGL ES, MongoDB/MySQL/Redis, dataset:coco,kitti,VOC lanuage:python/c/c++ 图像分类经典网络模型 LeNet-5 AlexNet VGG-16/VGG-19 GoogLeNet Inception v3/v4 ResNet preResNet ResNeXt SENet
目标检测网络模型:
R-CNN(Region-CNN)
SPP Net
Fast R-CNN
Faster R-CNN
R-FCN
YOLO
SSD
FPN
RetinaNet
目标检测常用数据集 Pascal VOC: http://host.robots.ox.ac.uk/pascal/VOC/ MS COCO : http://cocodataset.org/#home KITI: http://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=2d ImageNet: http://www.image-net.org/ Berkeley发布BDD100K: bdd-data.berkeley.edu/#download-section 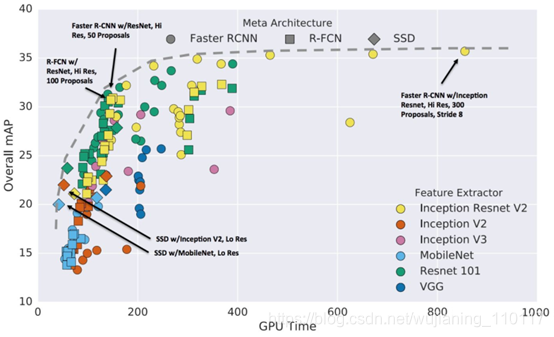
语义分割(semantic segmentation)
Mask R-CNN
FCN
SegNet
Unet
DeepLab
RefineNet
PSPNet
GCN
DeepLabV3 ASPP
GAN
目标检测常用数据集
Pascal VOC: http://host.robots.ox.ac.uk/pascal/VOC/
MS COCO : http://cocodataset.org/#home
KITI: http://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=2d
Cityscapes:https://www.cityscapes-dataset.com/dataset-overview/#features
ImageNet: http://www.image-net.org/
Berkeley发布BDD100K: bdd-data.berkeley.edu/#download-section
NYUDv2:https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html
SUN-RGBD:http://rgbd.cs.princeton.edu/
ADE20K_MIT:http://groups.csail.mit.edu/vision/datasets/ADE20K/
名称
优点
缺点
FCN
可以接受任意大小的图像输入;避免了采用像素块带来的重复存储和计算的问题
得到的结果不太精确,对图像的细节不敏感,没有考虑像素与像素之间的关系,缺乏空间一致性
SegNet
使用去池化对特征图进行上采样,在分割中保持细节的完整性;去掉全连接层,拥有较少的参数
当对低分辨率的特征图进行去池化时,会忽略邻近像素的信息
Deconvnet
对分割的细节处理要强于 FCN,位于低层的filter 能捕获目标的形状信息,位于高层的 filter能够捕获特定类别的细节信息,分割效果更好
对细节的处理难度较大
U-net
简单地将编码器的特征图拼接至每个阶段解码器的上采样特征图,形成了一个梯形结构;采用跳跃连接架构,允许解码器学习在编码器池化中丢失的相关性
在卷积过程中没有加pad,导致在每一次卷积后,特征长度就会减少两个像素,导致网络最后的输出与输入大小不一样
DeepLab
使用了空洞卷积;全连接条件随机场
得到的预测结果只有原始输入的 1/8 大小
RefineNet
带有解码器模块的编码器-解码器结构;所有组件遵循残差连接的设计方式
带有解码器模块的编码器-解码器结构;所有组件遵循残差连接的设计方式
PSPNet
提出金字塔模块来聚合背景信息;使用了附加损失
采用四种不同的金字塔池化模块,对细节的处理要求较高
GCN
提出了带有大维度卷积核的编码器-解码器结构
计算复杂,具有较多的结构参数
DeepLabV3 ASPP
采用了Multigrid;在原有的网络基础上增加了几个 block;提出了ASPP,加入了 BN
不能捕捉图像大范围信息,图像层的特征整合只存在于 ASPP中
GAN
提出将分割网络作为判别器,GAN 扩展训练数据,提升训练效果;将判别器改造为 FCN,从将判别每一个样本的真假变为每一个像素的真假
没有比较与全监督+半监督精调模型的实验结果,只体现了在本文中所提创新点起到了一定的作用,但并没有体现有效的程度
人脸识别
网络模型:
dlib
mtcnn
DeepFace
OpenFace
DeepID
Facenet
VGGFace
• 人脸识别常用数据集大全
• 哥伦比亚大学的公众人物脸部数据集: PubFig: Public Figures Face Database
• 香港中文大学大型人脸识别数据集: Large-scale CelebFaces Attributes (CelebA) Dataset
• color FERET Database: https://www.nist.gov/itl/products-and-services/color-feret-database
• Multi-Task Facial Landmark (MTFL) dataset: http://mmlab.ie.cuhk.edu.hk/projects/TCDCN.html
x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1amlhbmluZ18xMTAxMTc=,size_16,color_FFFFFF,t_70#pic_center)
• Video Codec
• H264/H265/H266
• Ffmpeg/Gstream/OpenMax
流媒体(Streaming Media)技术是指将一连串的媒体数据压缩后,以流的方式在网络中分段传送,实现在网络上实时传输影音以供观赏的一种技术。
流媒体实际指的是一种新的媒体传送方式,有声音流、视频流、文本流、图像流、动画流等,而非一种新的媒体。
流媒体文件格式是支持采用流式传输及播放的媒体格式。常用格式有:RA:实时声音;RM:实时视频或音频的实时媒体;RT:实时文本;RP:实时图像;SMII.:同步的多重数据类型综合设计文件;SWF:real flash和shockwavc flash动面文件;RPM: HTMI。文件的插件;RAM:流媒体的源文件,是包含RA、RM、SMIIJ文件地址(URL地址)的文本文件;CSF:一种类似媒体容器的文件格式,可以将非常多的媒体格式包含在其中,而不仅仅限于音、视频。quicktime,mov,asf,wmv,wma,avi,mpeg,mpg,dat,mts; aam多媒体教学课件格式,可将authorware生成的文件压缩为aam和aas流式文件播放。